
Using artificial intelligence to classify the status of kidney allograft in routine clinical records
Andrea García1, Juliana Cuervo-Rojas2, Juan Garcia-Lopez3, Fernando Girón-Luque1,4.
1Research Department, Colombiana de Trasplantes, Bogotá, Colombia; 2Epidemiology and Bioestatistics Department , Pontificia Universidad Javeriana , Bogotá, Colombia; 3Informatics and Technology Department, Colombiana de Trasplantes, Bogotá, Colombia; 4Transplant Surgery Department, Colombiana de Trasplantes, Bogotá, Colombia
Introduction: Electronic health records (EHRs) could be useful for research, but as they are not designed for this purpose, their use offers several practical challenges: regular access and selection of information that is generated at high volume and speed, expensive and time-consuming process of manual review and requirement of highly skilled personnel for identification and selection of relevant information with minimum error. Another major challenges in using these data is to identify the most relevant information, as the data in the EHRs are not collected for research purposes. Automated text classification using natural language processing (NLP) may help to overcome this challenge. The aim of this study is to develop an NLP algorithm to classify correctly the status (failure) of a kidney allograft in clinical records of kidney transplant recipients written in Spanish.
Methods: To train and evaluate the NLP tool, we used an annotated corpus of 61 382 clinical records from kidney transplant patients (n= 1 950) followed in Colombiana de Trasplantes from 2008 to 2021. A couple of trained clinicians who review every record classified graft loss events. We prepared the free text in the clinical records in several steps: data cleaning (removing punctuations, removing stop words, lower casing, tokenization and lemmatization), data transformation, data integration and data reduction. Using a machine learning model (random forests) we identified the most important words to classify graft loss in clinical texts. We used this model to classify the status of the graft in a testing dataset by using a method for validating the model (Bagging or Bootstrap Aggregation).
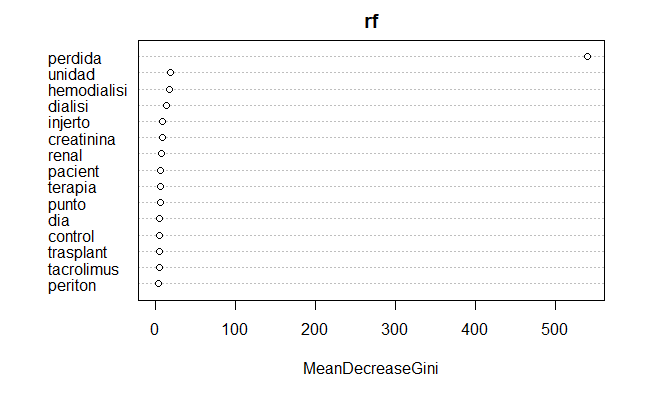
Results: A word cloud showed the most recurrent terms or concepts in the dataset. According to the mean decrease in Gini Score, the Spanish words that better identify graft loss in our clinical texts were: “pérdida”, “unidad” “hemodiálisis” and “diálisis”. The random forest model correctly classified 94% of the events of graft loss (540 /575).

Conclusion: A wealth of clinical histories remains locked behind clinical narratives in free-form text. NLP methods that automatically transform clinical text into structured data may help unlock the full potential of EHR data. We present promising preliminary results of an application of machine learning and NLP methods that classify automatically the status of kidney transplantation from unstructured text in routine clinical records, potentially helping to avoid the need of lengthy and expensive manual review for outcome classification in clinical research.

right-click to download